An ongoing point i've made for many years to programmers is the use of simple assembler instructions, and avoiding "FOR" within C/C++ code.
Below us a simple example of this for GCC
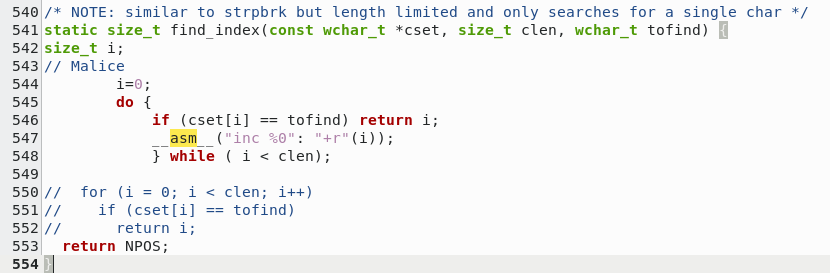 Firstly, you can see I removed the "FOR" loop and replaced with a "DO/WHILE" statement in order to use the increment command.
Secondly, I replaced where the "i++" with the assembler "INC".
Many like to make arguments over "For loops are better" and "using assembler opcodes don't make much difference". Both points i've demonstrated
multiple times in the past. People who believe this are usually "trained" by others who don't actually know how code is compiled and run, so
rather than repeat something i've demonstrated time after time, i've an assembler output of the original code being compiled for X64, and my updated code;
Firstly, you can see I removed the "FOR" loop and replaced with a "DO/WHILE" statement in order to use the increment command.
Secondly, I replaced where the "i++" with the assembler "INC".
Many like to make arguments over "For loops are better" and "using assembler opcodes don't make much difference". Both points i've demonstrated
multiple times in the past. People who believe this are usually "trained" by others who don't actually know how code is compiled and run, so
rather than repeat something i've demonstrated time after time, i've an assembler output of the original code being compiled for X64, and my updated code;
| Original output | Optimised output |
|---|
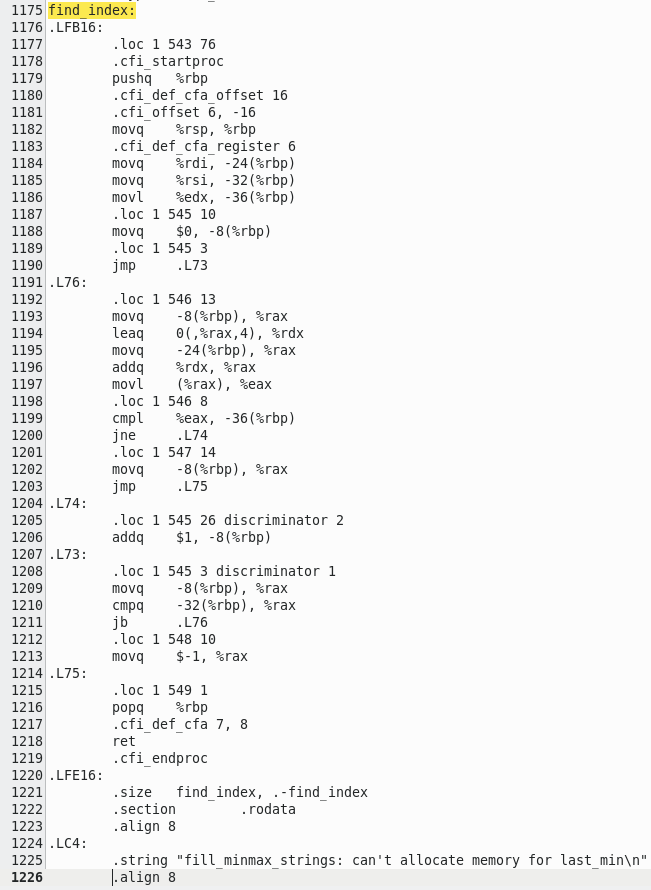 |  |
First thing to notice is my assembler insert loop is slightly larger than the original loop. This would seem to make the actual
loop take longer than before until you understand HOW the opcodes themselves work.
When you increment the memory location, it does just that without messing with too many other flags used by the processor, as opposed
to adding - which loads the location and various flags such as carry, adds 1 to the value (or more, flag depending), sets new values to the
flags and finally stores the result.
Let us look at Intels "INC" opcode versus the "ADD" opcode, notice that INC only sets flags on results, whereas ADD seems quite messy by comparison;
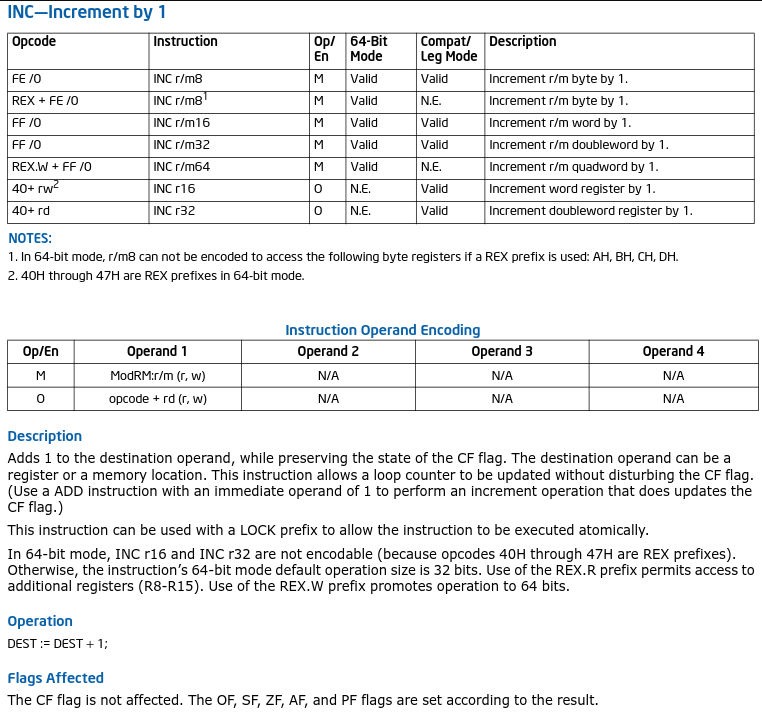
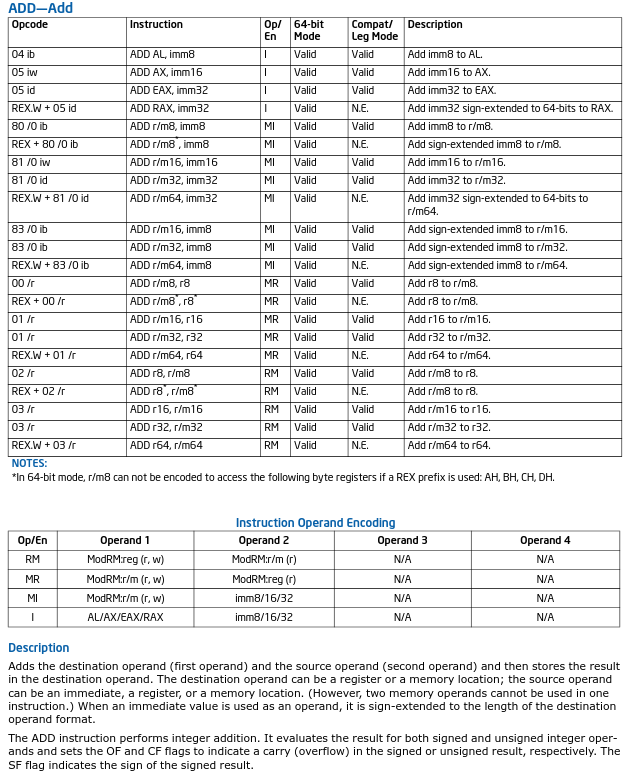
 In short, it's far better to use INC than ADD 1 for counting iterations for loops.
The original code also starts with a jump, which is very strange and I can only guess is one of the many bad quirks of C code when it is
compiled. When timing in code is more important then size, it's ALWAYS best to avoid using too many branches and jumps.
One of many tricks to achieve "repeating code" over "loops" is by writing a generator. Something i'm heavily a user of for smaller systems.
For example, you want to change the RGB values of a bitmap while it is being displayed, but in a cycle critical environment. A C code could
do this, but when compiled, C code is ALWAYS inefficient when faced against well written assembler code.
I would like to address the Intel Optimising C compiler. As a former Intel partner, I used their compiler a lot when toying with
various compression routines made by Matt Mahoney. His compression used context modelling with neural networking - which meant it was
very slow, and very CPU intensive. The overall gains by using the Intel Optimising compiler were there and on average about 10% faster code
at the expense of more code space being used by a significant size increase in the app itself - it would unroll loops (which I explained earlier). HOWEVER - it was still C code
and therefore could be optimised further. Yes, my hand-written code was over 15% faster with little extra app size increase - enough boasting.
In this case for the crunch routine, the actual size of the loop varies depending on the user input so we can not predict the size of the
actual loop iterations. Instead, we minimise the loop itself as much as possible and remove as many "FOR" loops with "DO/WHILE". Even doing this
will increase speed slightly at the cost of a few extra opcodes.
Given that the idea behind crunch is to generate wordlists, a very simple idea yet very time intensive, we can be forgiven for making the actual code itself
large for the sake of increased speed. By removing as many "FOR" loops, and replacing as many "[LABEL]++" with "INC [LABEL]" commands, you will
see a speed increase. This rule is universal and can also be applied to compression routines which you may well be using alongside
crunch. If you can shave a month off a years generating, then that is a worthy saving and not unreasonable.
In short, it's far better to use INC than ADD 1 for counting iterations for loops.
The original code also starts with a jump, which is very strange and I can only guess is one of the many bad quirks of C code when it is
compiled. When timing in code is more important then size, it's ALWAYS best to avoid using too many branches and jumps.
One of many tricks to achieve "repeating code" over "loops" is by writing a generator. Something i'm heavily a user of for smaller systems.
For example, you want to change the RGB values of a bitmap while it is being displayed, but in a cycle critical environment. A C code could
do this, but when compiled, C code is ALWAYS inefficient when faced against well written assembler code.
I would like to address the Intel Optimising C compiler. As a former Intel partner, I used their compiler a lot when toying with
various compression routines made by Matt Mahoney. His compression used context modelling with neural networking - which meant it was
very slow, and very CPU intensive. The overall gains by using the Intel Optimising compiler were there and on average about 10% faster code
at the expense of more code space being used by a significant size increase in the app itself - it would unroll loops (which I explained earlier). HOWEVER - it was still C code
and therefore could be optimised further. Yes, my hand-written code was over 15% faster with little extra app size increase - enough boasting.
In this case for the crunch routine, the actual size of the loop varies depending on the user input so we can not predict the size of the
actual loop iterations. Instead, we minimise the loop itself as much as possible and remove as many "FOR" loops with "DO/WHILE". Even doing this
will increase speed slightly at the cost of a few extra opcodes.
Given that the idea behind crunch is to generate wordlists, a very simple idea yet very time intensive, we can be forgiven for making the actual code itself
large for the sake of increased speed. By removing as many "FOR" loops, and replacing as many "[LABEL]++" with "INC [LABEL]" commands, you will
see a speed increase. This rule is universal and can also be applied to compression routines which you may well be using alongside
crunch. If you can shave a month off a years generating, then that is a worthy saving and not unreasonable.